Pretrain DQN with ISA
In the first post of our blog, we would like to talk about one useful trick that our team used at DeepHack.Game hackathon for improving the performance of the Google DeepMind’s Q-learning algorithm (DQN), the algorithm known for its ability to learn playing a variety of Atari 2600 games at human and superhuman levels.
As the name of the post suggests, the matter concerns a special technique for pretraining convolutional filters of Deep Neural Networks (DNNs) based on Independent Subspace Analysis (ISA), a multi-dimensional version of the well-known Independent Component Analysis (ICA). The idea of pretraining is not new; there are a number of publications on applying such tools of modern machine learning as Restricted Boltzmann Machines and autoencoders to initialization of weights in DNN architectures. ISA is not a common choice for this purpose. Nonetheless, it has several advantages; the main among them is ISA’s ability to generate a set of features (what in practice is almost equivalent to the task of constructing convolutional filters) that allows presenting each region of a processed image in the form of the expansion:
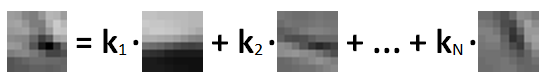
where the coefficients are as uncorrelated as possible. In other words, there is no or little overlapping of relevant information in each pair of features: each feature contains some portion of unique data. This property results in the reduction in the number of features and improvement of model’s generalization ability. Moreover, features produced with ISA are robust to local translation, but selective to frequency, rotation and velocity.
Following Quoc V. Le et al. (2011), we implemented ISA in the form of a neural network with a special structure:
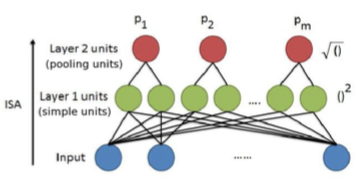
where the weights in the first layer with a square activation function are learned, and the weights of the second layer with a square-root activation function are fixed and (in our realization) set to be equal to identity matrix.
We have ported the Matlab realization of ISA to Torch and integrated the obtained code into the DQN framework. The pretraining procedure for the weights of convolutional neural network in DQN includes two main steps. First, ISA objective function is defined:
1
2
3
4
5
6
7
8
9
10
11
12
local ISA = function(W)
local Z = V * X
local P = H * torch.pow(W * Z, 2)
P:add(0.0001)
local J = torch.sum(torch.sqrt(P))
local F = H:t() * torch.pow(P, -0.5)
local dJ = torch.cmul((W * Z), F) * Z:t() / X:size(2)
return J, dJ
end
Here, is PCA whitened game screen patches stored in . Second, while training, after each stochastic gradient descent step, orthonormalization of weights is carried out by expression , where the inverse square root of the matrix implemented in the function sqrtmi as follow:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
function sqrtmi(w)
-- find eigenvectors
local e,v = torch.eig(w, 'V')
e = e[{{},1}]
-- eliminate eigenvectors whose eigenvalues are zero
local indices = torch.linspace(1,e:size(1),e:size(1)):long()
local i = indices[torch.gt(e, 0)]
e = e:index(1,i)
v = v:index(2,i)
-- inverse square root
return v * torch.diag(e:pow(-0.5)) * v:t()
end
For demonstrating the advantages of the suggested trick, we compare (i) DQN with random weight initialization with (ii) DQN with ISA pretrained weights in the convolution network on Kung-Fu Master game:
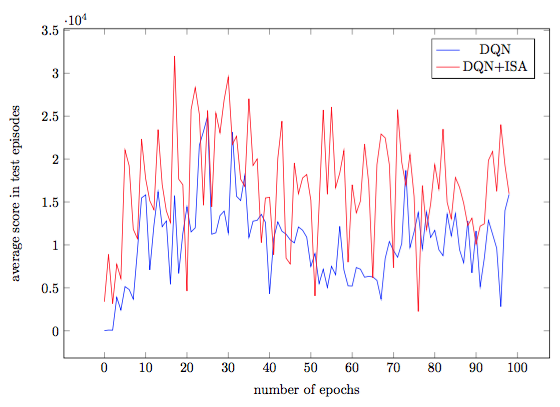
As you can see, the average score the agent receives (especially at the beginning of the training) is higher for DQN+ISA than for DQN.