Deep Attention Recurrent Q-Network
In December 2015 our paper in which we proposed a way of equipping Google DeepMind’s Deep Q-Network (DQN) with “soft” and “hard” attention mechanisms was presented at Deep Reinforcement Learning Workshop conducted for the first time within NIPS Conference.

|

|

|
There are several types of attention mechanisms (Cho et al., 2015). In our work, we use so-called content-based attention that envisages computing the relevance of each spatially, temporally or spatio-temporally localized region of the input. In particular, we stick to the approach suggested by Xu et al. (2015) for the domain of image caption generation.
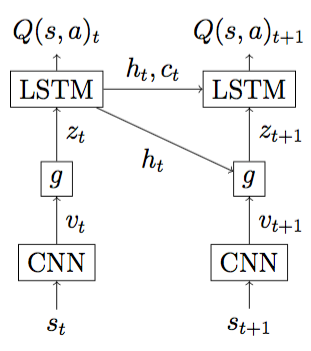
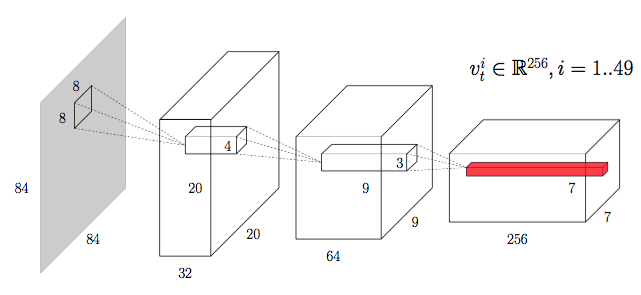
Architecture of the suggested Deep Attention Recurrent Q-Network (DARQN) consists of three main components depicted in the Figure above: convolutional network (CNN), attention network , and recurrent network (in this case LSTM). CNN processes input image, producing location vectors (see Figure below), each of which is associated with a specific area of the input image.
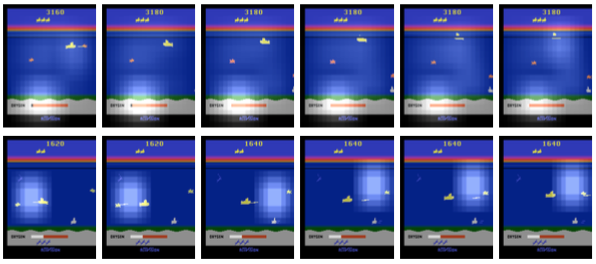
Attention network takes (, ) and determines relative importance of each corresponding area for the decision making process at the current moment of time. The resulting importance weights are used to calculate a context vector that is fed to the LSTM network. There are (at least) two ways how may be computed. In “soft” attention mechanism, is defined as a product of averaging all location vectors with . In “hard” attention mechanism, is equal to one of the with a probability defined by some -parametrized probability distribution (e.g. categorical distribution). To visualize attention regions, we create 256 subsidiary features maps 7 × 7 filled by measured importance of each location vector and then upsample these maps through CNN layers (see Picture below, “soft” attention at the top and “hard” version at the bottom, the corresponding game videos are available at our youtube channel).
Tests of the proposed DARQN model on some Atari 2600 games demonstrate level of performance superior to that of DQN. In the table below, the best among 100 epochs average rewards per episode for four different models on five Atari games are presented. One epoch corresponds to 50,000 steps. The hard and soft attention models as well as DRQN are trained with 4 unroll steps. DRQN weights are updated at each step, whereas DQN and DARQN weights are updated one time per 4 steps.
| Breakout | Seaquest | S. Invaders | Tutankham | Gopher | |
|---|---|---|---|---|---|
| DQN | 241 | 1,284 | 916 | 197 | 1,976 |
| DRQN | 72 | 1,421 | 571 | 181 | 3,512 |
| DARQN hard | 20 | 3,005 | 558 | 128 | 2,510 |
| DARQN soft | 11 | 7,263 | 650 | 197 | 5,356 |
Our realization of DARQN is based on the source code and is available online.